
















뉴스속보

비즈니스워치 | 2025-07-03 13:16:02
[비즈니스워치] 한수연 기자 papyrus@bizwatch.co.kr

KT가 '한국적 인공지능(AI)'를 전면에 내세워 AI 대중화에 나선다. 글로벌 빅테크 협력에서 자체 개발로 인공지능(AI) 사업의 무게추를 옮겼다. 독자 개발한 AI인 한국어 특화 거대언어모델(LLM) '믿:음 2.0'의 오픈소스를 공개하고 상업적 이용까지 푼 것이다. 새 정부 들어 소버린 AI(주권형 AI) 중요성이 강조되고 있는 것과 무관치 않은 것으로 풀이된다.
KT는 자체 생성형 AI 연구조직인 젠 AI랩(Gen AI Lab)이 개발한 '믿:음 2.0'의 오픈소스를 AI 개발자 플랫폼 허깅페이스에 공개한다고 3일 밝혔다. 믿:음 2.0은 115억 파라미터의 '믿:음 2.0 베이스'와 23억 파라미터의 '믿:음 2.0 미니' 두 종류로, 기업·개인·공공기관 등 누구나 제약 없이 사용할 수 있는 게 특징이다. 한국어와 영어를 지원한다.
믿:음 2.0은 KT가 2023년 선보인 1.0 버전의 차세대 모델이다. 이번에 개발·공개한 2.0 버전은 파라미터 규모와 학습 데이터, 한국어 처리 능력 등을 전면적으로 고도화했다.
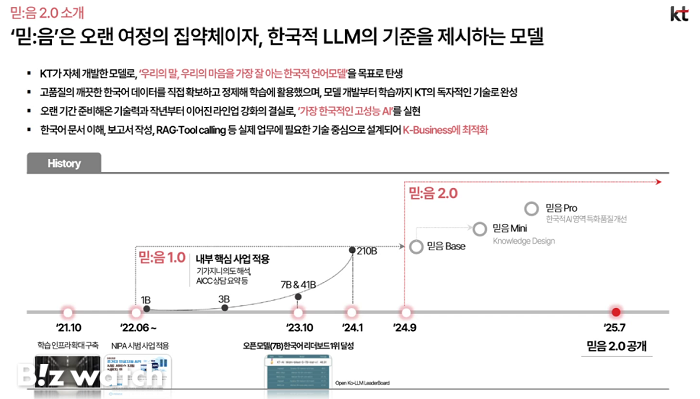
KT는 특히 한국의 문화와 언어를 잘 이해하도록 개발한 한국적 AI라는 점을 강조했다.
신동훈 KT 젠 AI 랩장(CAIO) 상무는 이날 진행한 언론 브리핑에서 "한국적 가치에 중점을 두고 튜닝했기 때문에 한국 문화나 역사와 관련한 질문에 굉장히 잘 답변을 할 수 있고 한국적 뉘앙스나 미세한 감정 표현 또한 잘 캐치한다"며 "110억 파라미터 이상의 한국어 범용 LLM을 누구나 상업적으로 활용할 수 있는 오픈소스로 공개한 것은 KT가 처음으로 국내 AI 생태계 활성화에 긍정적인 역할을 할 수 있을 것"이라고 말했다.
이를 위해 믿:음 2.0은 국내 교육용 도서와 문학 작품, 발간물, 법률, 특허 문서, 사전 등 다양한 산업·공공·문화 영역에서 방대한 한국 특화 데이터를 학습했다. 이 과정에서 저작권 이슈가 있는 데이터는 제거해 윤리성을 높였다. 한국어와 한국 문화·사회 등의 전문 분야에서 기존의 국내외 주요 모델을 상회하는 이해력과 생성 성능도 입증했다. 실제 KT와 고려대학교가 공동 개발한 한국어 AI 역량 평가 지표인 'Ko-Sovereign(코-소버린)' 벤치마크에서 유사 규모의 국내 기성 모델을 비롯해 글로벌 최고 수준의 오픈소스 모델을 능가하는 점수를 기록했다.
이번 믿음 2.0 발표로 KT의 AI 개발 방향에도 변화가 감지된다. 마이크로소프트(MS) 등 빅테크와 협력을 전면에 내세우던 전략에서 독자 개발 AI 모델에 무게추를 싣고 있기 때문이다. 소버린 AI 전략을 기반으로 글로벌 AI 3강 도약을 내건 새 정부 기조에 발맞추려는 행보로 분석된다.
KT는 정부의 '독자 AI 파운데이션 모델' 프로젝트에 참여할 의향도 공식화했다. 신 상무는 "국가 기간 통신사업자로 자체 AI 기술 개발을 한번도 포기한 적이 없다. 생성형 AI 원천기술을 확보하고 만들어가야 한다고 생각한다"며 "KT의 AI 철학과 방향이 맞기 때문에 독자 AI 파운데이션 모델 프로젝트에 참여하려고 준비하고 있다"고 설명했다.

ⓒ비즈니스워치(www.bizwatch.co.kr) - 무단전재 및 재배포금지











- 한줄 의견이 없습니다.
한마디 쓰기현재 0 / 최대 1000byte (한글 500자, 영문 1000자)

※ 광고, 음란성 게시물등 운영원칙에 위배되는 의견은 예고없이 삭제될 수 있습니다.